AI Agent Security: Challenges, Real Incidents, and What Organizations Must Do
AI agents (the increasingly agentic assistants that can read, act, and connect to tools and services) bring big productivity gains — and a fresh, unusual attack surface. Below I explain the main security challenges, show recent real-life incidents that illustrate them, and give practical steps organizations should take.
AI Agent Risks (what makes agents different & riskier)
Agents are often connected to cloud storage, email, code repositories, devtools, and internal APIs. That means a single malicious input can flow through many systems.
Unlike a chat model, agentic systems can act (create files, send emails, call APIs). That ability allows adversaries to weaponize models for lateral movement and data theft.
If an agent reads or ingests attacker-controlled content (docs, tickets, calendar invites), that content can contain hidden instructions that change agent behavior.
Some attacks require no user click — a poisoned document, email, or ticket the agent automatically processes can trigger exfiltration.
Even state-of-the-art models can be coaxed into disclosing secrets or giving illicit instructions via clever adversarial inputs.
Agents rely on connectors, plugins, SDKs, and third-party integrations. Vulnerabilities in those components (or in their auth tokens) can cascade into major breaches.
Recent real-world incidents (what actually happened)
I summarized key, reported incidents so you can see the threat in the wild — details below are drawn from public reporting and researcher write-ups.
| Incident | Date | Type | What went wrong | Why it matters |
|---|---|---|---|---|
| Lenovo "Lena" chatbot XSS vulnerability | Aug 2025 (patched Aug 18) | Prompt injection / XSS | Crafted prompt + HTML output caused browser to leak session cookies → potential account hijack / lateral movement. | Shows classic web vulnerabilities + model output can be chained into browser exploits. IT Pro |
| AgentFlayer / EchoLeak zero-click attacks | Jun–Aug 2025 (research disclosures) | Indirect prompt injection / zero-click | Malicious documents or tickets parsed by agents (Google Drive, Jira, Copilot connectors) caused silent exfiltration of secrets and files. | Demonstrates zero-click exfiltration where no user action is required. The Hacker News |
| GPT-5 jailbreak disclosures | Aug 2025 | Model jailbreak / guardrail bypass | Researchers found narrative patterns that bypassed model guardrails, coaxing illicit outputs. | Even newest models need engineering defenses — "safe by default" is not guaranteed. The Hacker News |
Some statistics (what the industry is saying)
- 93% of security leaders are bracing for daily AI attacks in 2025, per Trend Micro 's State of AI Security report. That's a useful framing: this is not a niche threat anymore.
- Multiple security vendors and researchers are publicly demonstrating zero-click and indirect prompt injection attacks — these techniques are actively being weaponized. The Hacker News
Attack patterns you should care about
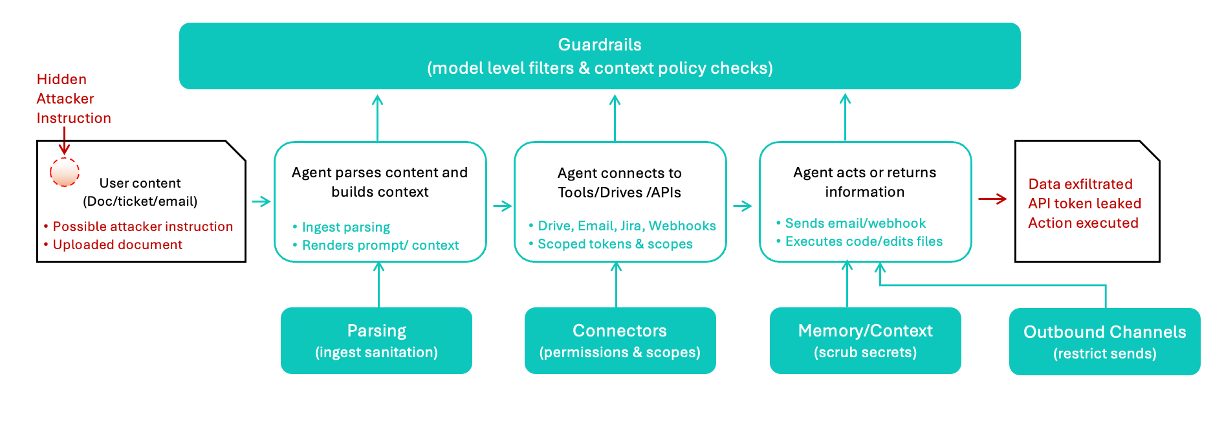
This diagram illustrates the typical flow of AI agent attacks and highlights critical security choke points where organizations can implement defensive measures.
Practical controls (what organizations must do)
Filter, sanitize, and canonicalize every input an agent will parse. Treat model outputs as code or untrusted HTML and sanitize before rendering.
Connectors to drives, repos, and cloud resources should use scoped tokens, short lifetimes, and require explicit approval for high-sensitivity scopes.
If an agent doesn't need to send emails or call webhooks, turn those capabilities off.
Extend pen testing to include agent workflows: craft poisoned documents, tickets, and data to see what the agent will do. Use adversarial prompt tests and zero-click simulations.
Verify provenance of documents and content. Use signed documents / verification where possible and flag untrusted sources.
Don't let agents retain secrets in long-lived memory. Rotate keys and scrub sensitive items from context windows.
Ensure every agent action is logged, can be traced to a user/trigger, and there's an automated "stop" control to revoke an agent's permissions quickly.
Watch for anomalous outbound requests, unusual file access, and unexpected API calls from agent service accounts.
Evaluate connectors, plugins, and third-party vendors for security hygiene and patch cadence. Expect vulnerabilities in third-party chatbots and widgets.
Quick decision matrix (how to prioritize mitigation)
High priority (fix now): any agent that has write access to cloud repos, emails, or can exfiltrate PII/credentials.
Medium priority: agents that can read sensitive docs or generate code/actions but are behind strict tokens.
Lower priority: agents used for benign, isolated tasks with no sensitive connectors.
Example checklist (copy for your security playbook)
- Limit connector scopes and use ephemeral tokens.
- Sanitize outputs before rendering to web clients.
- Run agent-specific red-team exercises every quarter.
- Enforce strict context retention policies and secret scrubbing.
- Implement an agent permission "break glass" kill switch.
- Monitor outbound traffic from agent service accounts.
- Subscribe to GenAI incident trackers ({[object Object]).
Final thought — balance productivity with safety
Agentic AI will change workflows, but the tools that make agents powerful also make them fragile security-wise. The good news: many mitigations are straightforward engineering and policy changes — validate input/output rigorously, minimize privileges, and build agent-aware monitoring and red-team processes. The faster organizations treat agents as a new class of infrastructure, the less likely they'll be the next "Lenovo Lena" or EchoLeak headline. IT Pro The Hacker News